Texterkennung (OCR) mit Adobe Acrobat Pro
Für die Volltextsuche von Librario ist es entscheidend, ob eine hochgeladene PDF-Datei Text enthält oder nicht. Wenn Sie eine Publikation selbst gescannt haben oder Librario die Fehlermeldung “Erkannter Text ist kurz. Bitte überprüfen Sie die Datei” anzeigt, müssen Sie eine Texterkennung (OCR) über die PDF-Datei laufen lassen.
Ein Programm, das in vielen Büros bereits installiert ist und Texterkennung beherrscht, ist Adobe Acrobat Pro (nicht zu verwechseln mit dem kostenfreien Adobe Acrobat Reader).
Screenshots zeigen Adobe Acrobat XI
Die Screenshots in dieser Anleitung stammen aus Adobe Acrobat XI Pro. Neuere Versionen von Adobe Acrobat Pro sind ähnlich aufgebaut; die Bezeichnungen der Funktionen können leicht abweichen.
Als Beispiel dient ein Inhaltsverzeichnis, das Librario beim Import mit Kennung automatisch heruntergeladen hat.
Schritt 1: Texterkennung starten
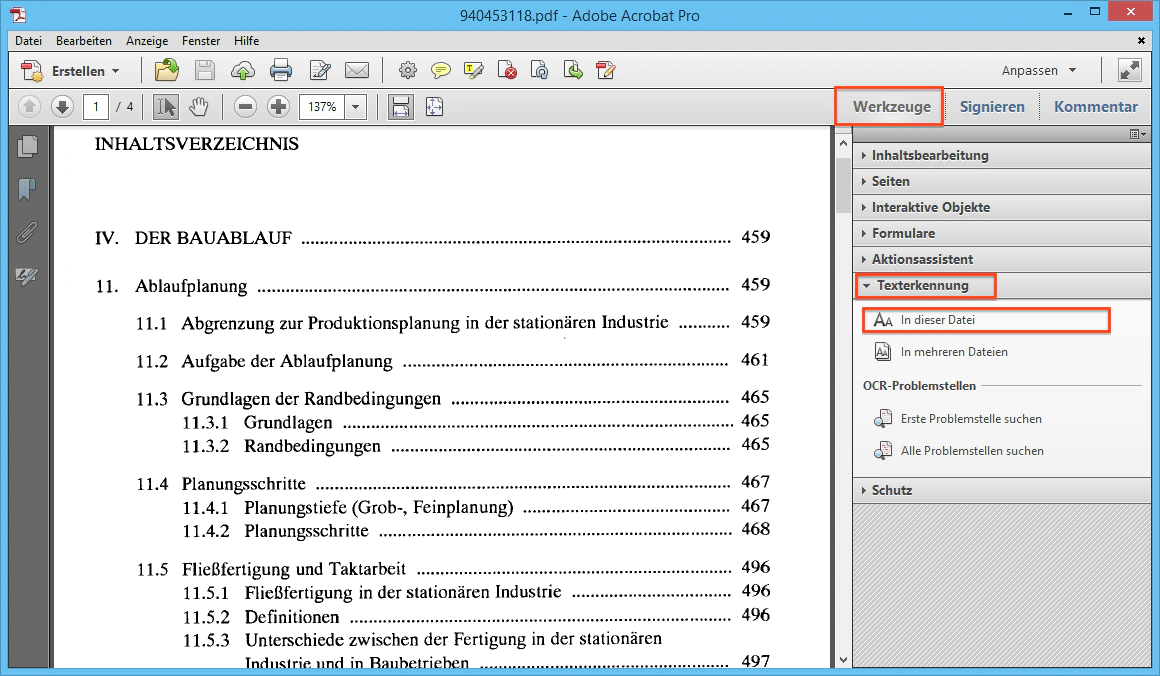
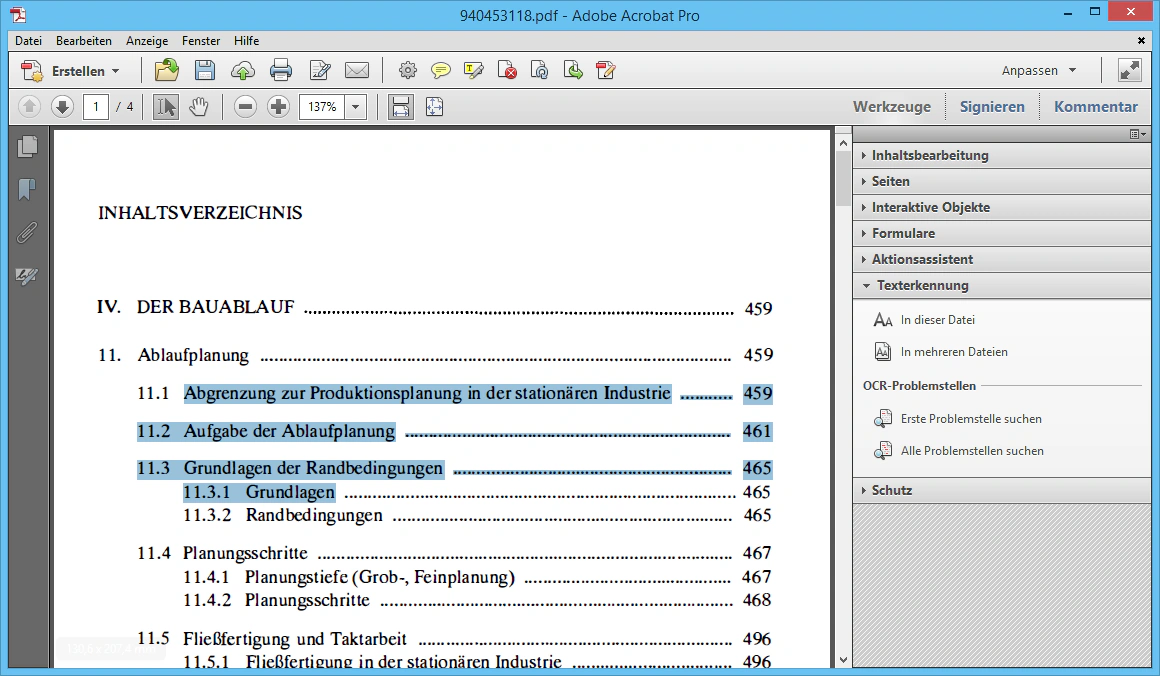
Auf der rechten Seite befindet sich die Werkzeugleiste von Adobe Acrobat. Sie enthält verschiedene Funktionen, mit denen Sie PDF-Dateien bearbeiten können. Klicken Sie auf den Reiter “Texterkennung” und wählen Sie den Punkt “In dieser Datei”.
Schritt 2: Texterkennung konfigurieren
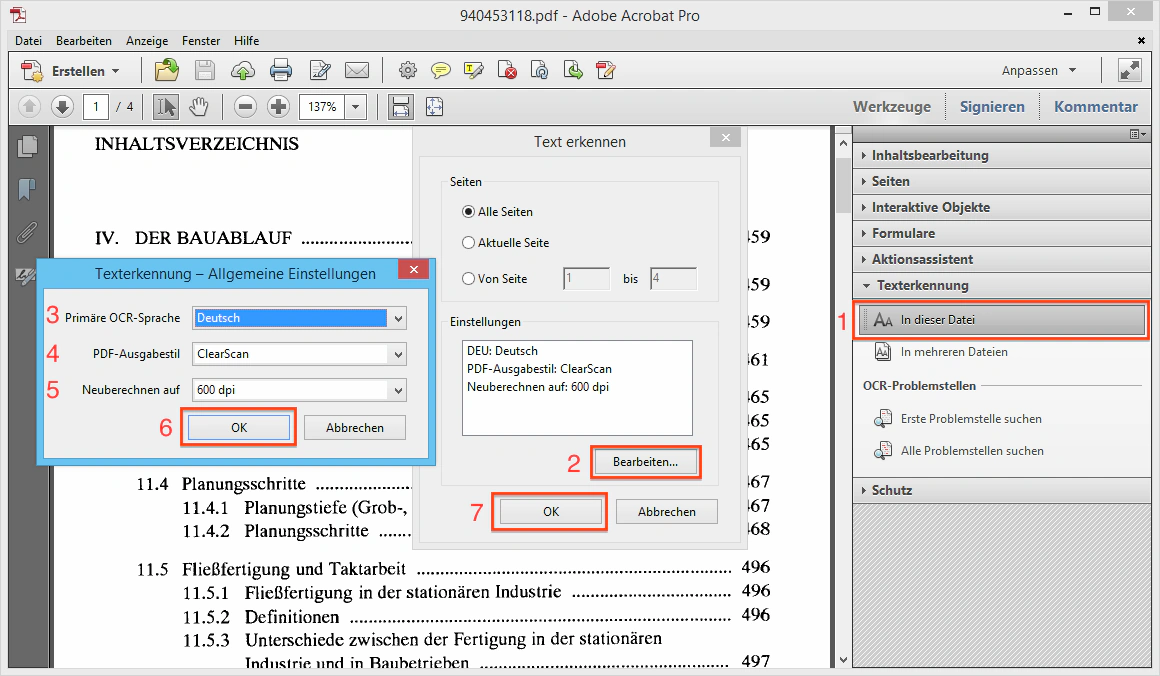
Als Nächstes legen Sie die Einstellungen für die Texterkennung fest:
- Die Sprache des Dokuments: Adobe Acrobat Pro arbeitet je Sprache mit einem anderen Wortschatz, der hilft, die richtigen Zeichen und Wörter zu erkennen.
- Der PDF-Ausgabestil “ClearScan”: laut Adobe die beste Option für möglichst kleine und möglichst wenig verpixelte PDF-Dateien.
- Neuberechnen auf: auf den höchstmöglichen Wert festlegen.
Schließen Sie beide Dialogfelder jeweils mit “Ok”.
Schritt 3: Weitere Optimierungen
Mit der Texterkennung sind Sie eigentlich fertig. Vergessen Sie nicht, die neue PDF-Datei zu speichern.
Sie können die PDF-Datei aber noch weiter optimieren. Ziel ist, die Dateigröße so weit wie möglich zu reduzieren: Je kleiner die Datei, desto schneller können Anwender sie später aus Librario herunterladen und öffnen.
Verwenden Sie dazu den Aktionsassistenten “Gescannte Dokumente optimieren”. Klicken Sie in der Werkzeugleiste auf “Aktionsassistent” und dort auf “Gescannte Dokumente optimieren”.
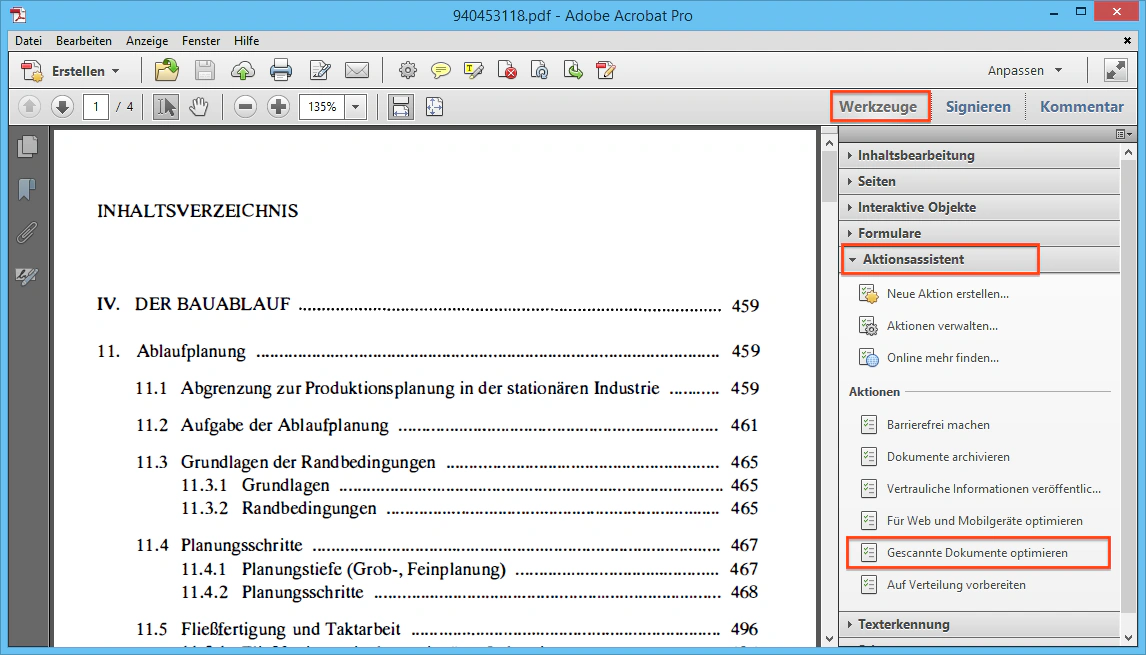
Der Assistent durchläuft drei Aufgaben:
- Dokumentbeschreibung hinzufügen
- Gescannte PDF-Datei optimieren
- Datei speichern unter
Klicken Sie auf “Anfang”, um den Assistenten zu starten.
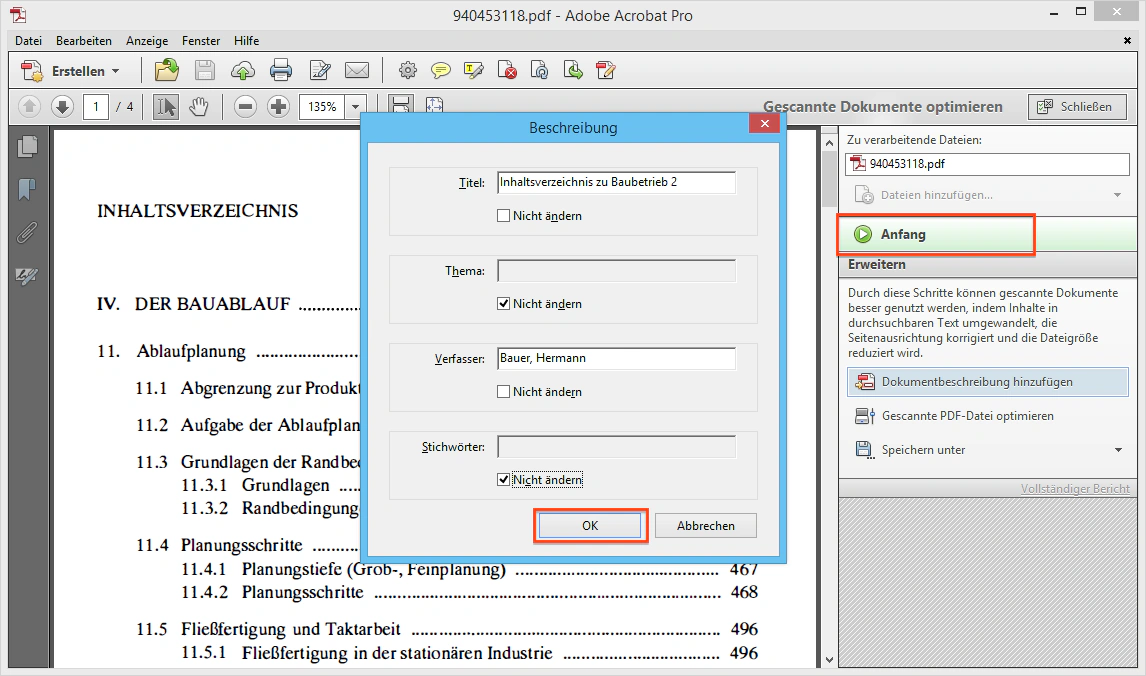
Schritt 3a: Dokumentbeschreibung hinzufügen
Geben Sie hier den Titel sowie den Verfasser (Autor) der Publikation an. Librario liest diese Informationen später als PDF-Metadaten wieder aus.
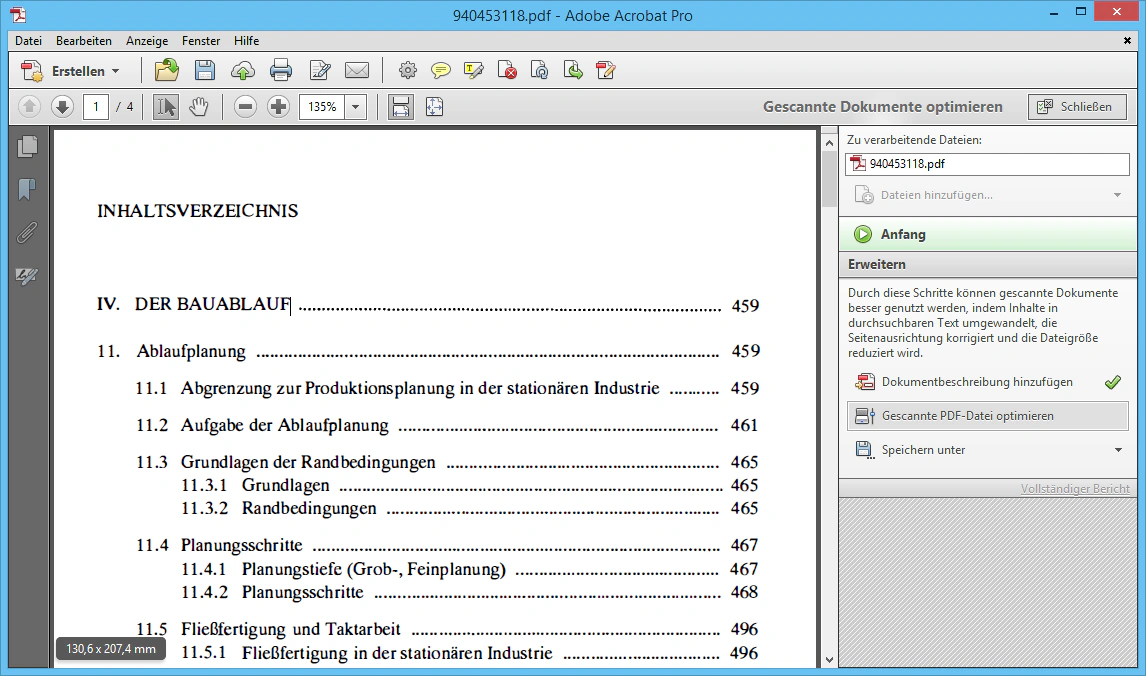
Schritt 3b: Gescannte PDF-Datei optimieren
Dieser Schritt läuft automatisch ab und optimiert die interne Struktur der PDF-Datei.
Schritt 3c: Datei speichern unter
Anschließend speichern Sie die neue Datei. Sie können dabei die alte Datei überschreiben oder die Datei unter einem anderen Namen neu speichern.
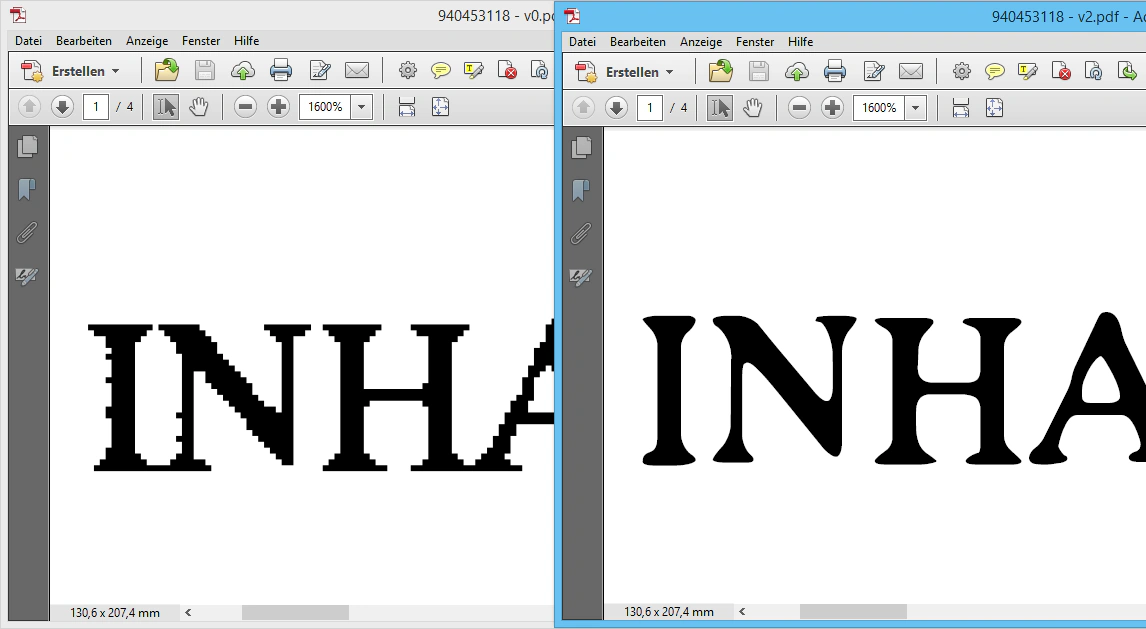
Das Ergebnis ist eine deutlich kleinere Datei (im Beispiel um 46 %), die außerdem besser aussieht und von Librarios Volltextsuche durchsucht werden kann.
Allgemeine Hinweise zu durchsuchbaren Dateien, etwa zu anderen OCR-Programmen, Scan-Einstellungen und Qualitätskontrolle, finden Sie unter Dateien für die Volltextsuche optimieren.